目标检测(Object Detection)是计算机视觉中一个重要分支,其定义就是在给定的图片中精确找到物体所在位置,并标注出物体的类别。其主流方法包括R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD等。主要难点在于物体尺寸变化大、物体摆放角度不同、出现位置随机、多物体、多类别等等。
参考文献:https://www.julyedu.com/question/big/kp_id/32/ques_id/2103
目标检测常见算法
- 传统目标检测算法:
- 算法流程:基于滑动窗口的区域选择策略 + HOG/SIFT(提取特征) + SVM/Adaboost(分类器分类)
- 主要问题:
- 滑动窗口的策略没有针对性,时间复杂度高,窗口冗余
- 手工设计特征鲁棒性不高
- 候选框+深度学习分类:
- 算法流程:提取候选区域,并用相应区域以深度学习的方法进行分类,如:
- R-CNN: Selective Search + CNN + SVM
- SPP-net: ROI Pooling
- Fast R-CNN: Selective Search + CNN + ROI
- Faster R-CNN: RPN +CNN + ROI
- R-FCN
- 算法流程:提取候选区域,并用相应区域以深度学习的方法进行分类,如:
- 基于深度学习的回归方法:YOLO/SSD/DenseBox等;以及结合RNN的RRC detection;结合DPM的Deformable CNN等
如何解决定位的问题?
因为初期是单目标检测,因此就是分类和定位这两个问题。而图像分类问题已经有很好的网络来提取图像特征了,那么此时如何做定位就是一个问题。
思路一:看做回归问题,预测(x,y,w,h)这四个参数
- 先搭建一个图像分类的网络,在这个基础上fine-tuning一下
- CNN提取特征部分不变,将网络尾部展开,加上Classification head和Regression head
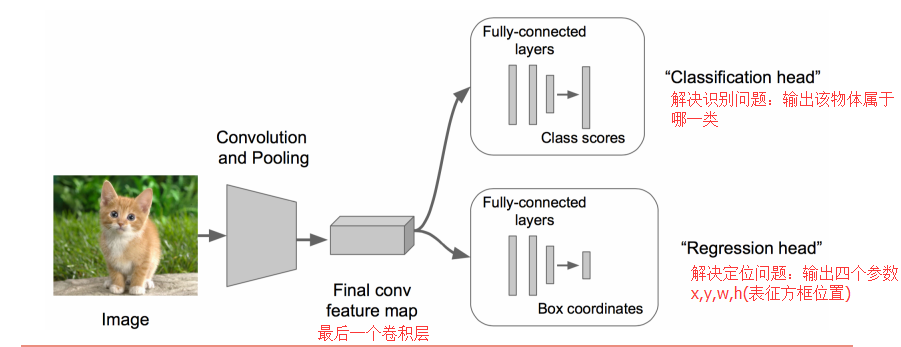
- 其中Regression部分利用欧氏距离损失,并使用SGD训练
- 预测阶段将2个头拼上,完成不同的部分
上述步骤需要两次fine-tuning,第一次在AlexNet上;第二次在将头改为regression head后,前面保持不变,做一次fine-tuning。
Regression的收敛速度太慢,尝试用Classification代替回归,因此只是fine-tuningregression head,且前面参数值保持不变
- 思路二:先取框,对每个框都利用分类头和回归头,这里分类头输出的是一个score,代表了当前框的分数,而回归头同样也是回归(x,y,w,h)这四个参数,但我没搞懂为什么回归?
- 问题:框要取多大?怎么移动?
- 取不同大小的框,步长为1的从左上移动到右下。此时时间复杂度高,窗口冗余严重
以上均是单个目标的检测,而对于多目标的检测而言,需要优化上述滑动窗口的方法
候选窗+深度学习分类
R-CNN:Region-based Convolution Networks
- 算法步骤
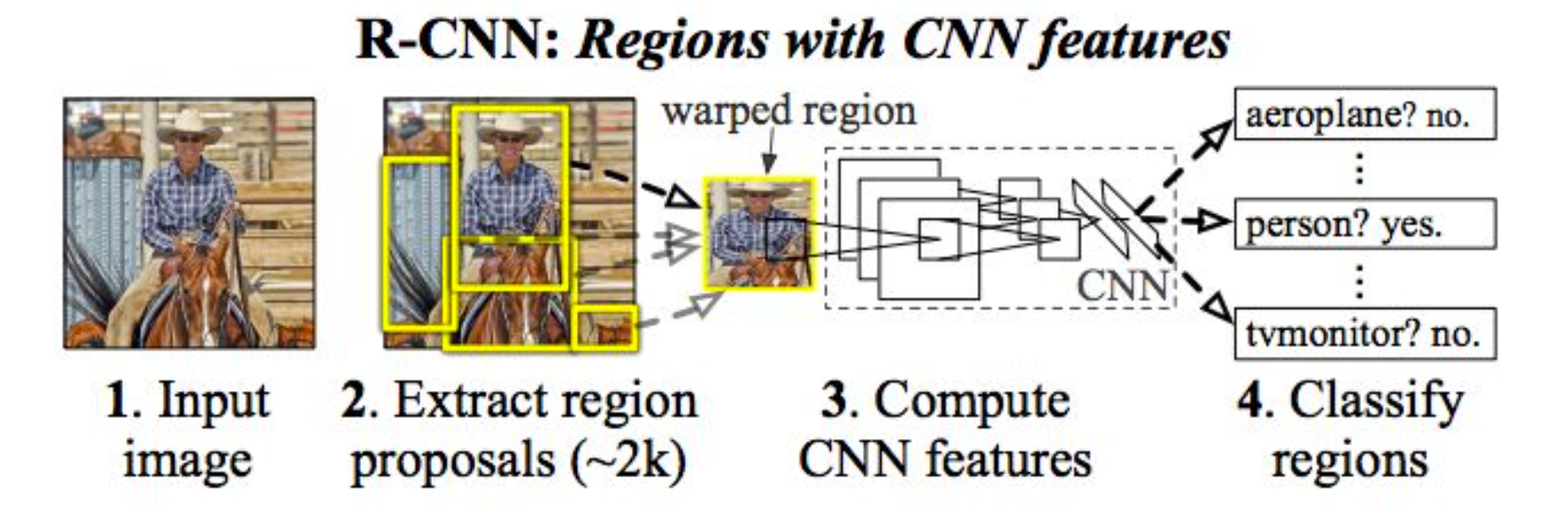
补充
什么是IoU?
全称为Intersection-over-Union,即交并比,即检测框与GT框之间的交集面积除以并集的面积,用于评估检测框与GT之间的差距。
在目标检测中,模型通常会生成大量(~2000)的候选框,根据每个框的置信度排序,以此计算框与框之间的IoU,并用非极大值抑制NMS删除多余的检测框
**为什么以此计算框与框之间的IoU?NMS具体是什么?

